

AI success depends on more than clean data models, it requires a shared enterprise ontology that gives consistent meaning to customers, accounts and transactions across every system.
For most of banking technology history, the application was king. Core systems defined what data existed, where it lived, and how it moved. Data architecture was downstream. It adapted to what the applications needed.
AI reverses this entirely.
Intelligent systems do not adapt to whatever data structure the applications happen to produce. They require data that is clean, consistent, semantically clear, and architecturally governed. When the data is not ready, the AI is not useful. When the data is broken, the AI makes confident, expensive mistakes.
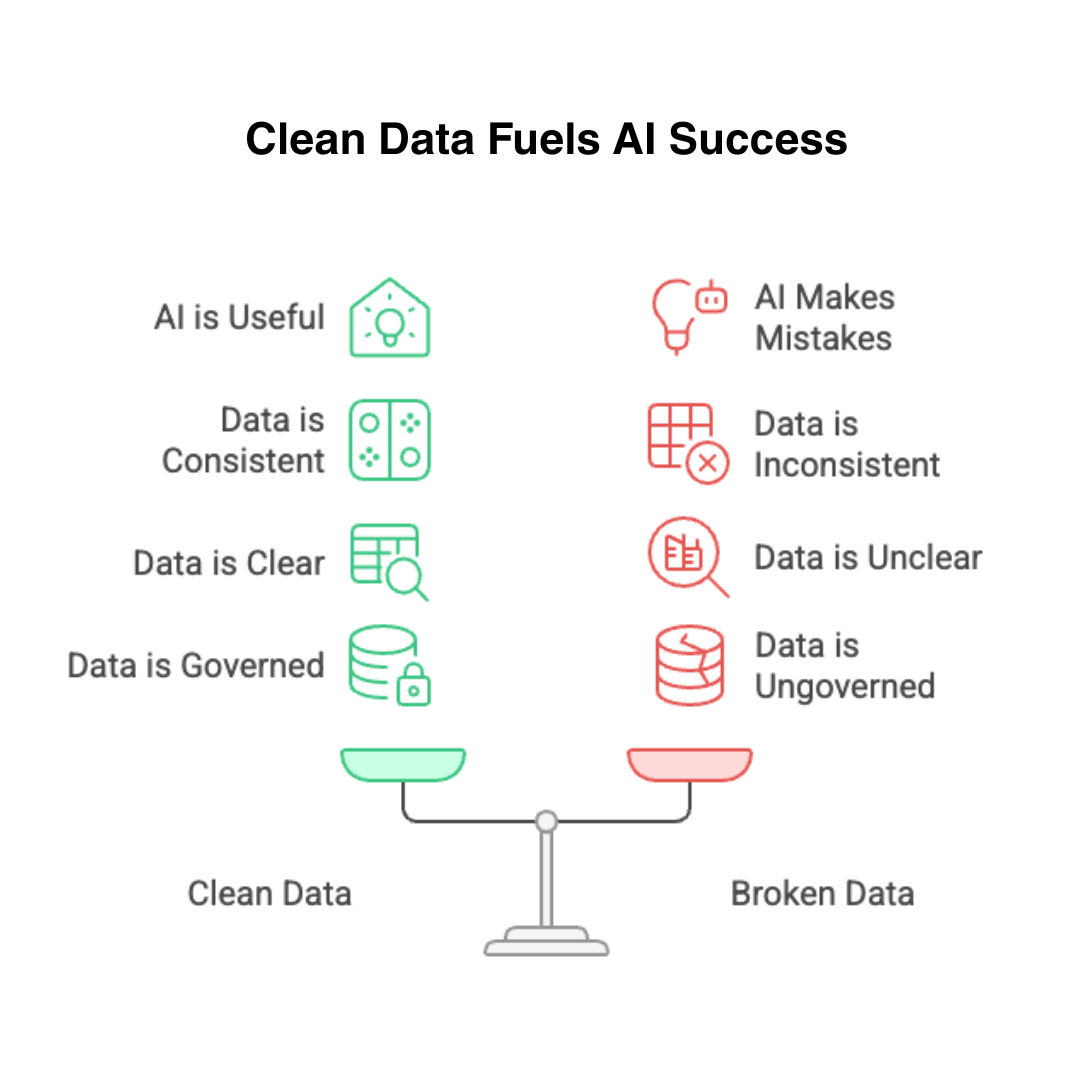
Clean, governed data enables reliable AI. Broken data guarantees mistakes.
This is not a data quality campaign. It is an architectural shift. Data must now be designed first, with everything else built to serve it.
What Changed and Why It Matters Now
In our second article in this series, we examined how patchwork modernization fails under AI pressure. The core problem was integration — too many point-to-point connections, inconsistent schemas, no shared context across systems.
Data architecture is the underlying cause of most of that damage.
When each system owns its own definition of a customer, an account, or a transaction, integration becomes translation. Every connection requires mapping. Every new consumer inherits the inconsistency. AI models trained on this data learn the confusion rather than the truth.
Banks that have invested in shared data architecture — canonical models, governed ontologies, clear lineage — are discovering that AI deployment is significantly faster and more reliable. Not because they bought better AI tools. Because their data was ready.
Two Layers Banks Must Get Right
We have watched banking technology teams conflate these two layers for years. In most institutions, they are treated as the same problem. They are not.
The first layer is structural. Data models, schemas, tables, relationships, constraints. This is how data is stored and retrieved. Most banks have this — though it is often fragmented across systems of record, shaped by the requirements of each application rather than designed around the enterprise.
The second layer is semantic. This is the enterprise ontology — the shared vocabulary that defines what customermeans, what account means, what relationship means, consistently across every system in the bank. This is where we see the most significant gaps. Not because banks have not tried, but because ontology work is harder, slower, and less visible than application delivery. It rarely shows up in a vendor demo.
AI needs both. The structural layer gives it data to work with. The semantic layer gives it meaning.
Without shared meaning, an AI system that pulls customer data from the core, the CRM, and the fraud platform is working with three different definitions of the same entity. It cannot reason coherently across them.
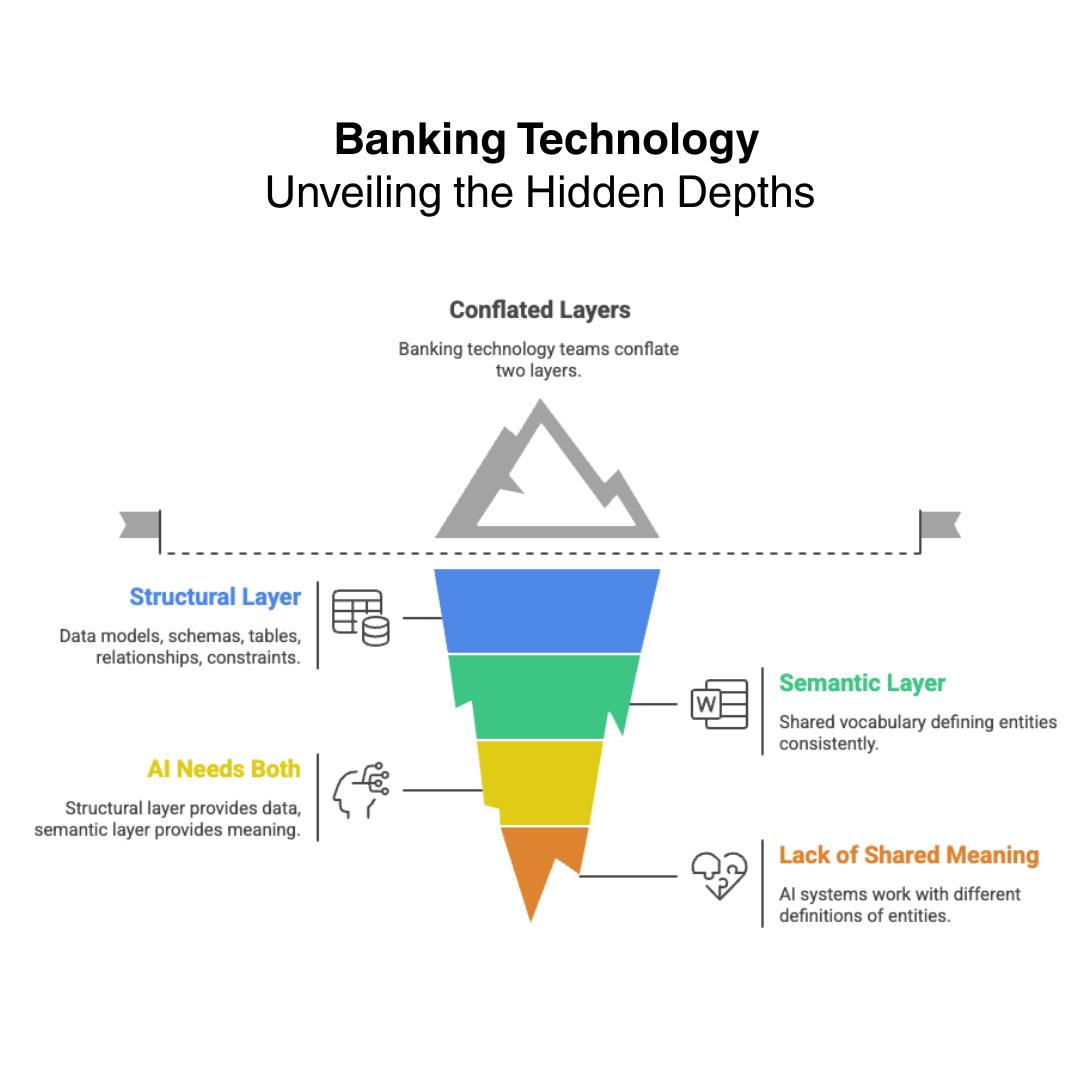
AI requires both structure and meaning: data models provide the structure, ontologies provide the shared enterprise meaning.
The Structural vs. Semantic Gap: A Comparison Across
Your Systems
AI-ready systems require both strong structural architecture and shared semantic meaning across data.
To make this concrete, consider how a typical mid-size bank’s three key systems handle the same concepts today and the gap between structural definition and semantic meaning:
| Dimension | Core Banking System | CRM System | Mortgage System |
|---|---|---|---|
| Data Model: “Customer” | Account holder with a CIF number and deposit/loan relationship | Any contact with a relationship record — including prospects who have never opened an account | A borrower tied to a specific loan origination, often a separate entity class from the deposit customer |
| Ontology: What “Customer” Means | An active account relationship | A pipeline or portfolio relationship, including pre-customers | A transaction participant in a credit event |
| Data Model: “Account” | A deposit or loan product instance with an account number | Typically not a native concept — references the core via integration | The mortgage loan itself — often a separate product class with its own attributes |
| Ontology: What “Account” Means | A financial product the bank owns | A relationship touchpoint | A secured credit obligation |
| Data Model: “Relationship” | Direct customer-to-account link (usually 1:many) | A full contact hierarchy: household, company, individual, advisor network | A borrower-coborrower-guarantor structure specific to the loan |
| Ontology: What “Relationship” Means | Product ownership | Business development potential | Credit risk distribution |
| Data Model: “Transaction” | A posted financial event with amount, date, channel, and account code | An interaction record — meeting, call, proposal | A payment, fee, or escrow movement against the mortgage |
| Ontology: What “Transaction” Means | A money movement | A sales or service event | A loan lifecycle event |
This is what an AI system is navigating when it tries to reason across these three platforms. Every row in that table is a semantic collision waiting to happen. The AI is not wrong — it is working with what it was given. The architecture is what needs to change.
What This Looks Like When It Breaks
Consider a mid-size commercial bank deploying an AI-powered next-best-action engine for its relationship managers. The model itself is sound — trained on transaction patterns, product usage, and lifecycle signals. It should be able to tell a banker: this client is likely to need a treasury management upgrade within 90 days.
But the engine pulls “customer” from three systems. The core defines customer as an account holder with a CIF number. The CRM defines customer as any contact with a relationship record, including prospects who have never opened an account. The digital banking platform defines customer as an authenticated user with login credentials.
The AI does not know these are different definitions. It treats them as the same entity. The result: the next-best-action engine recommends treasury services to prospects who have no accounts, flags dormant digital users as high-engagement clients, and misses actual relationship deepening opportunities because the CIF-based customer record lacks the behavioral data sitting in the digital platform.
The model is not broken. The ontology is.
The cost is not theoretical either. A bank running a fraud detection model that defines “account” as a deposit relationship will miss fraud on loan accounts entirely if the core system treats loan accounts as a separate entity class. Worse, it will generate false positives when legitimate transactions cross the definitional boundary between what the fraud system considers an account and what the core considers one. Every false positive costs the bank a customer interaction, a manual review, and a measurable erosion of trust. Multiply that across thousands of daily transactions and the operational cost of an ungoverned ontology becomes impossible to ignore.
The Assessment Question
Before any bank invests in AI tooling, the honest question to ask is this: if we asked five systems — the core, the CRM, the data warehouse, the fraud platform, and the reporting layer — what a customer is, would we get five consistent answers?
Most banks already know the answer. The answers would differ. Some systems would have overlapping but incompatible definitions. Some would be missing fields that others consider essential. Some would have stale data that no one has reconciled in years.
This is not a data governance presentation problem. It is an architectural fact that determines how quickly and safely AI can be deployed.
A Canonical Definition Is Not a Data Governance Project
We have seen this conflated enough times that it is worth stating directly. Building enterprise ontology is not a data governance initiative. It is not a steering committee. It is not a policy document.
It is an architectural decision about who owns the definition of each core business entity — and a technical commitment to ensuring every system that creates or consumes that entity conforms to the shared definition.
A canonical customer definition exists across the enterprise. It is not owned by the core system, the CRM, or the data warehouse. It is owned by the data architecture. Every system that creates or consumes customer data conforms to it.
Account, product, transaction, relationship — each has a single authoritative definition with documented lineage showing where it originates, how it transforms, and where it flows. New AI use cases do not require custom data extraction and transformation projects. They connect to governed data products that are already clean, documented, and trusted. When a model produces a recommendation or flags an anomaly, the data lineage is traceable end to end. Regulators can follow the chain. Auditors can reproduce the output.
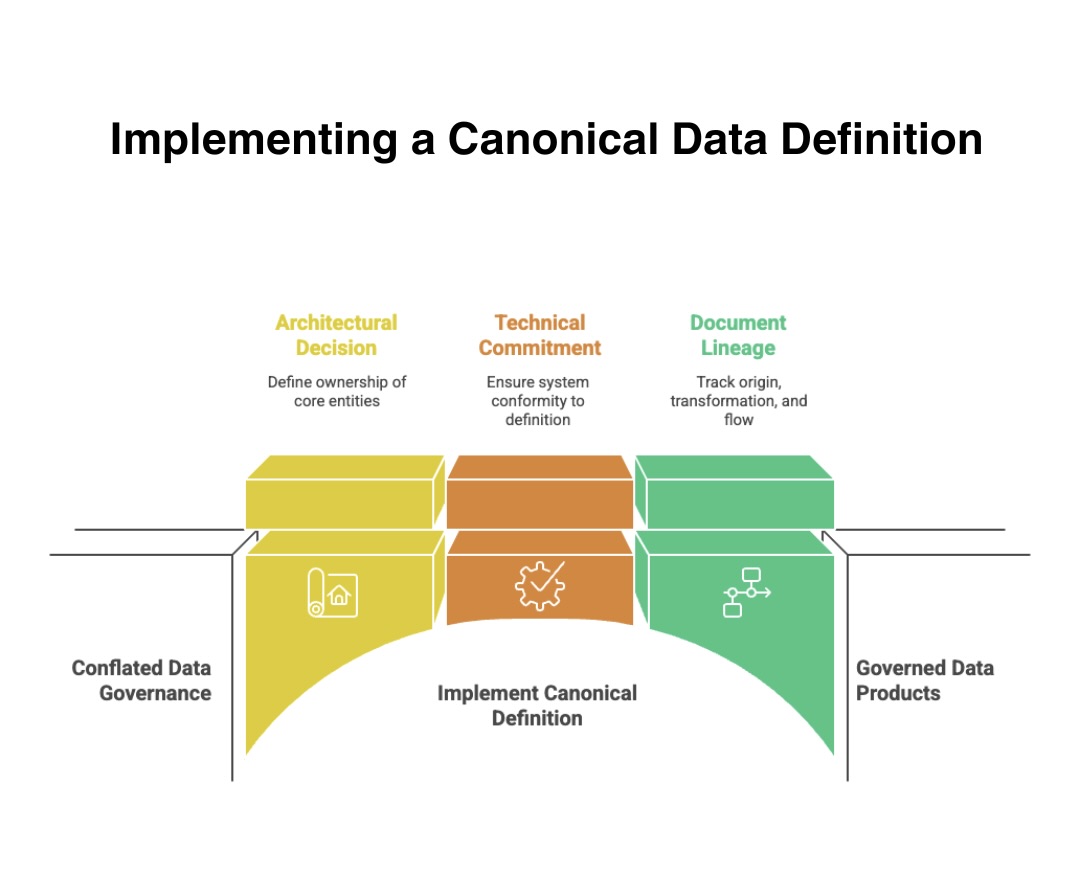 Canonical data definitions turn fragmented governance into governed, trusted enterprise data.
Canonical data definitions turn fragmented governance into governed, trusted enterprise data.
What Comes Next
In our fourth article in this series, we move from the realities of current architecture to the modernization pathways themselves. The question shifts from what is broken to how to fix it and how to do it in sequence without stopping the bank in its tracks.
Data architecture does not fix itself as a side effect of other modernization work. It requires deliberate design, executive sponsorship, and a long enough time horizon to build properly. Banks that treat it as a downstream consideration will find themselves rebuilding it under pressure, which is always more expensive and more disruptive than doing it once, intentionally, in advance.
The hierarchy has shifted. Data architecture now determines what is possible. Everything else follows.
Where to Start
If your bank has not yet mapped the semantic gap across its systems of record, that is the first move. Not a technology purchase. Not a vendor evaluation. A structured analysis of how each platform defines the entities your AI will need to reason across.
Core System Partners works with banks navigating exactly this challenge — from initial data architecture assessments to enterprise ontology design and AI readiness roadmaps. If your team is serious about deploying AI that performs, contact us to start the conversation.
Previous article in the series: Why patchwork modernization breaks under AI
Return to: Why AI makes modern core banking architecture non-negotiable




