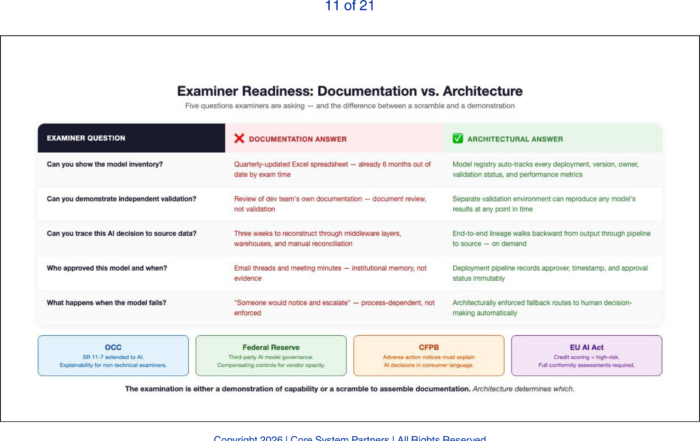
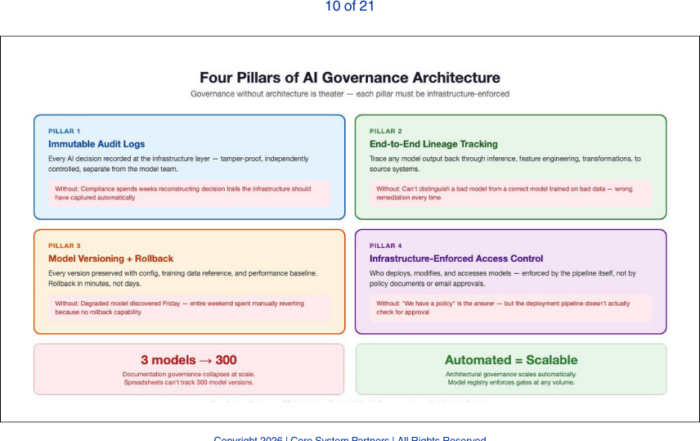
When one paper jam halts your core banking system, it’s not a printer problem—it’s an architecture problem.
Not long ago, I walked into a regional bank that had gone into full panic mode. The teller system froze, ATMs were stalled, and transaction processing had ground to a halt. The culprit? A network printer in the back office had jammed. That’s not a punchline. That’s what actually happened.
This cartoon might make you laugh, but for those of us in banking IT, it’s also a bit of a horror story. A single peripheral error cascading into a full system outage? That’s not just a tech quirk—it’s a red flag waving over your core architecture.
Let’s talk about the fragility hiding in plain sight and what it really says about your readiness for transformation.
Why This Happens: A Legacy Built on Quick Fixes
Many legacy core systems were built for a world that no longer exists. They were designed in the ‘90s—or earlier—when centralized control and physical devices were tightly coupled with transaction logic. Need to print a customer receipt? Sure—just embed that print confirmation step into the transaction flow itself. What could go wrong?
Well… everything. Because once you hardwire interdependencies, even something as benign as a failed print job can block critical processing paths. And over time, as patches and bolt-ons accumulate, the system becomes less a streamlined engine and more a Jenga tower of fragility.
Here’s what usually happens behind the scenes:
- Printer service fails.
- Core system’s print confirmation thread gets stuck.
- Transaction queues get locked.
- Error logging overwhelms storage.
- Operators start rebooting systems just to “unstick” the process.
That’s not banking. That’s duct tape engineering.
The Real Cost of These Outages
Let’s not sugarcoat it: every unnecessary failure undermines trust.
- Customers lose confidence. If your app says “Transaction Error” instead of “Payment Confirmed,” users notice—and they remember.
- Staff get demoralized. Nothing drains your IT or operations team faster than fighting battles with ghosts of outdated infrastructure.
- Regulators raise eyebrows. Systemic fragility is a risk management concern, not just a tech inconvenience.
- Transformation gets harder. You can’t build agile digital services on top of brittle plumbing.
When Your Architecture Is Holding You Hostage
You shouldn’t need a PhD in reverse-engineering just to figure out why a core process failed. Yet, in many banks, that’s the norm.
If you’re relying on:
- Hard-coded logic that assumes every component is always online,
- Monolithic batch jobs that can’t tolerate a hiccup,
- Dependencies between transaction workflows and physical hardware,
…then you’re not just running legacy—you’re running risk.
So, How Do We Fix It?
This isn’t about upgrading printers. It’s about upgrading assumptions. If you want a system that won’t grind to a halt over small failures, you need resilience by design.
Here’s where to start:
1. Decouple physical from digital
Design your workflows so that printers, scanners, or external devices are optional—never blockers.
“No single point of failure should have the power to pause core banking operations.”
2. Introduce failure tolerance
Use asynchronous processing where possible. If something breaks, it should retry or queue—not crash.
3. Audit system interdependencies
Run a mapping exercise to identify what systems depend on each other, directly or indirectly. You’ll be surprised how many paths trace back to a “temporary patch” no one wants to touch.
4. Implement graceful degradation
If one component fails (e.g., a document renderer), the rest of the transaction should still complete. Defer the non-essential steps.
5. Invest in real-time observability
You can’t fix what you can’t see. Proactive monitoring helps catch weird behavior before it takes the system down.
Real-World Example: From Fragile to Future-Ready
One of our clients—a mid-size bank in Southeast Asia—had a system dependency where teller transactions couldn’t close unless a printer successfully completed a passbook update. When the thermal printer jammed, everything stopped.
We worked with their team to decouple device confirmation from core processing, introduce a fallback queuing system, and move exception handling into a sidecar service. The result?
- 80% reduction in support tickets related to printer or scanner issues.
- Zero downtime from hardware-related process blocks in over 12 months.
- Teams freed up to focus on modernization instead of firefighting.
Why This Matters for Transformation
If you’re planning a core modernization, your existing system’s fragility is more than a nuisance—it’s a clue.
A transformation isn’t just about replacing old systems with new ones. It’s about making sure your next core doesn’t recreate the same brittle, tightly coupled architecture in shinier packaging.
Closing Thought: Fix the Foundation Before You Build Up
Look, we all love shiny dashboards and slick mobile apps. But if a printer error can still derail your institution’s ability to process a transaction, you’ve got bigger problems than user experience.
It’s time to ask hard questions:
- Can your systems degrade gracefully?
- Are your dependencies mapped and understood?
- Could one overlooked patch bring your bank to a halt?
If the answer is “I’m not sure,” that’s your starting point.
Ready to Find the Cracks in Your Foundation?
Our OptimizeCore® Scorecard helps banks uncover hidden risks in their current stack—so they can build forward with confidence, not chaos.
Because in a modern bank, your tech should scale and survive, a paper jam.
#CoreBankingTransformation #CoreBankingOptimization