
AI-driven banks face a new kind of operational risk: systems that remain online while models silently degrade, making incorrect decisions at scale without triggering traditional alerts
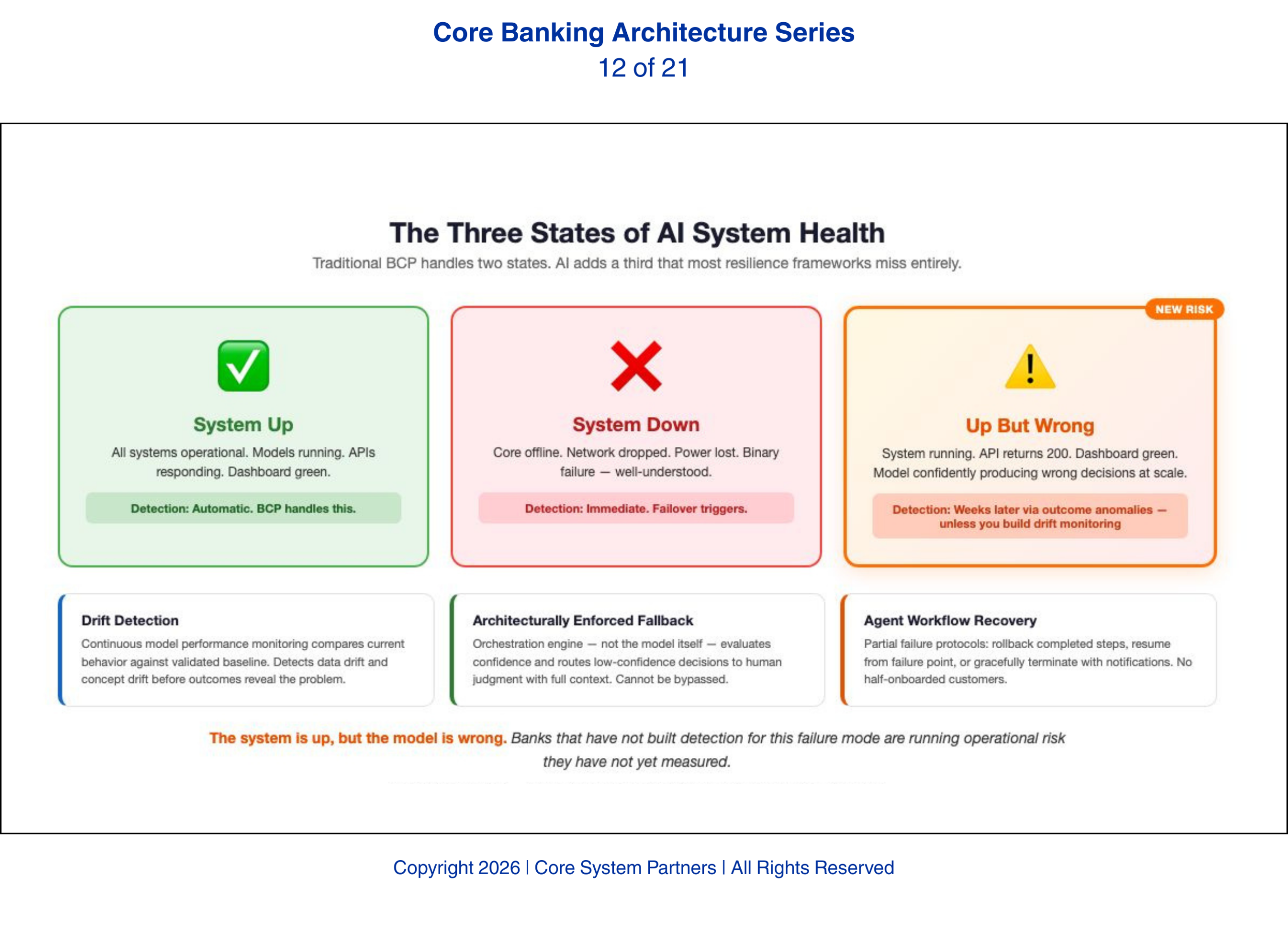
Every bank has a business continuity plan. Every plan assumes the same thing: that failures announce themselves. The core goes down. The network drops. The data center loses power. These are binary states — up or down — with well-understood detection and response protocols that BCP teams have spent decades perfecting.
AI breaks that assumption. AI introduces a failure mode that binary resilience frameworks cannot handle: the system is up, but the model is wrong.
The system is up, but the model is wrong.
The Invisible Failure
A degraded AI model does not crash. It does not throw errors. It does not trigger infrastructure alerts. It continues to operate, producing outputs that look structurally correct but are substantively wrong. A fraud detection model experiencing data drift might start approving transactions it should flag, or flagging transactions it should approve. The API returns a valid response. The status code is 200. The monitoring dashboard shows green. The model is confidently wrong.
This invisible failure is fundamentally different from the failures banks have trained for. It does not announce itself. It does not trigger a failover. It simply produces bad decisions at scale until someone notices the outcomes — and noticing outcomes takes time. A fraud model that stops catching fraud does not produce an immediate signal. The signal comes weeks later when fraud losses spike and the investigation traces backward to the model’s degradation.
We have seen this exact pattern at institutions that believed their monitoring was comprehensive. Infrastructure monitoring told them everything was fine. The model had been drifting for weeks. By the time the outcome data caught up, the exposure was already material.
Banks that have not built detection capability for this failure mode are running operational risk they have not yet measured.
Model Performance Monitoring and Drift Detection
The first resilience capability AI-driven banks need is continuous model performance monitoring with automated drift detection. This is not the same as infrastructure monitoring. Infrastructure monitoring tells you the model is running. Performance monitoring tells you the model is running correctly.
Drift detection works by continuously comparing a model’s current behavior against its validated baseline. When the statistical properties of the model’s inputs change — data drift — or when the relationship between inputs and outputs shifts — concept drift — the monitoring system detects the deviation and triggers an alert. The alert does not come from the infrastructure layer. It comes from a dedicated model monitoring system that understands what the model should be doing and can detect when it stops doing it.
Banks that do not have this capability are flying blind. Their infrastructure monitoring tells them the plane is in the air. Only model monitoring can tell them the plane is heading for the wrong destination.
Fallback Logic and Human-in-the-Loop Escalation
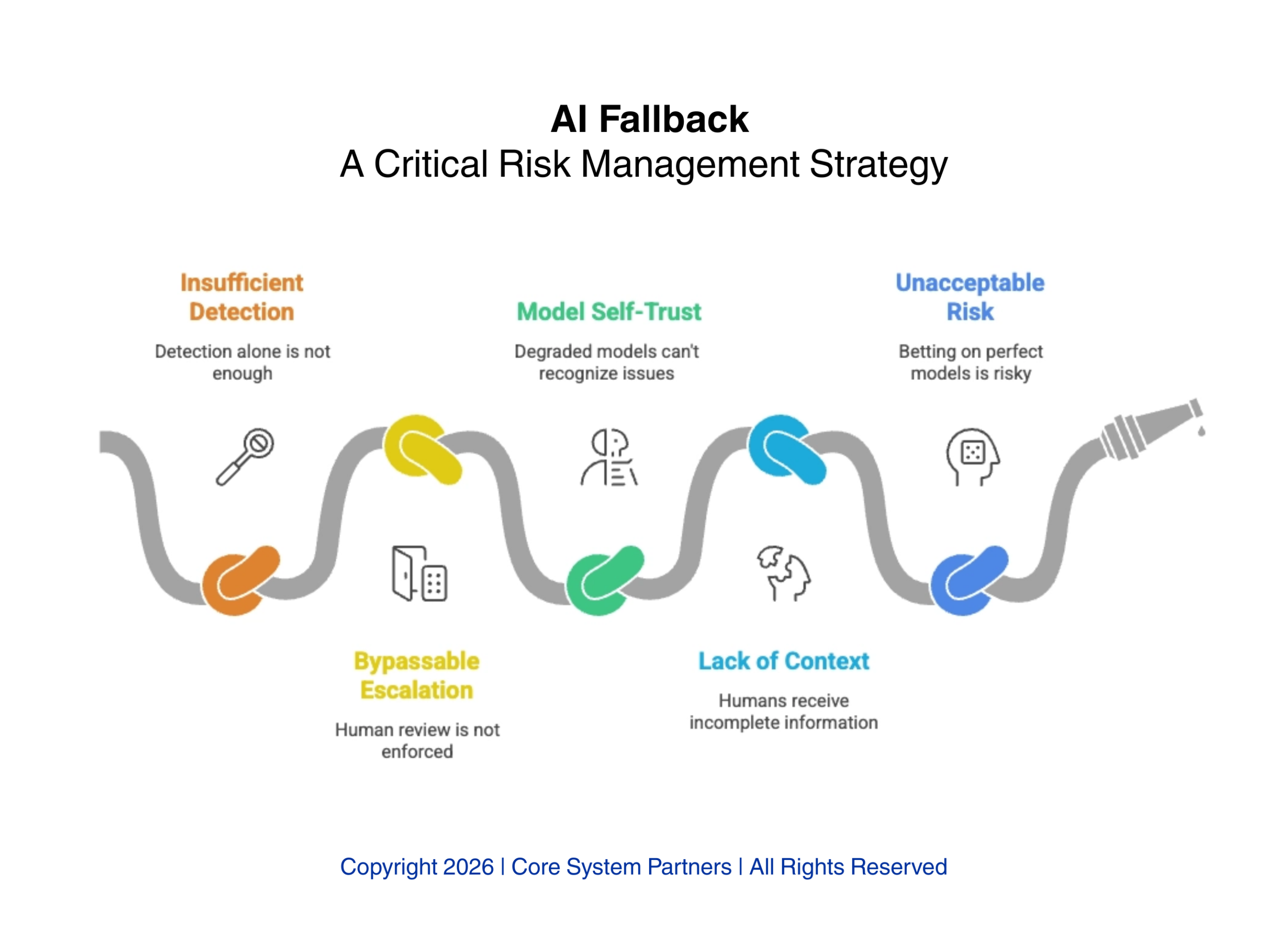
Detection is necessary but not sufficient. When drift is detected or model confidence drops below a defined threshold, the bank needs a fallback path. That fallback must route decisions to human judgment — not as a suggestion that a human review might be nice, but as an architecturally enforced escalation that cannot be bypassed.
The fallback logic must be built into the orchestration layer, not into the model itself. A degraded model cannot be trusted to recognize its own degradation and route to a human. The orchestration engine — the system that calls the model and acts on its outputs — must independently evaluate model confidence and make the routing decision. When confidence is high, the decision proceeds automatically. When confidence drops or drift is detected, the decision routes to a human queue with full context: what the model recommended, why confidence is low, and what data informed the recommendation.
Banks that design AI workflows without architecturally enforced fallback are betting that their models will never degrade. That is not a bet any risk manager should accept.
AI fallback is not optional, without enforced escalation, context and monitoring, degraded models can silently introduce unacceptable risk into banking operations.
Orchestration Engine Redundancy and Agent Recovery
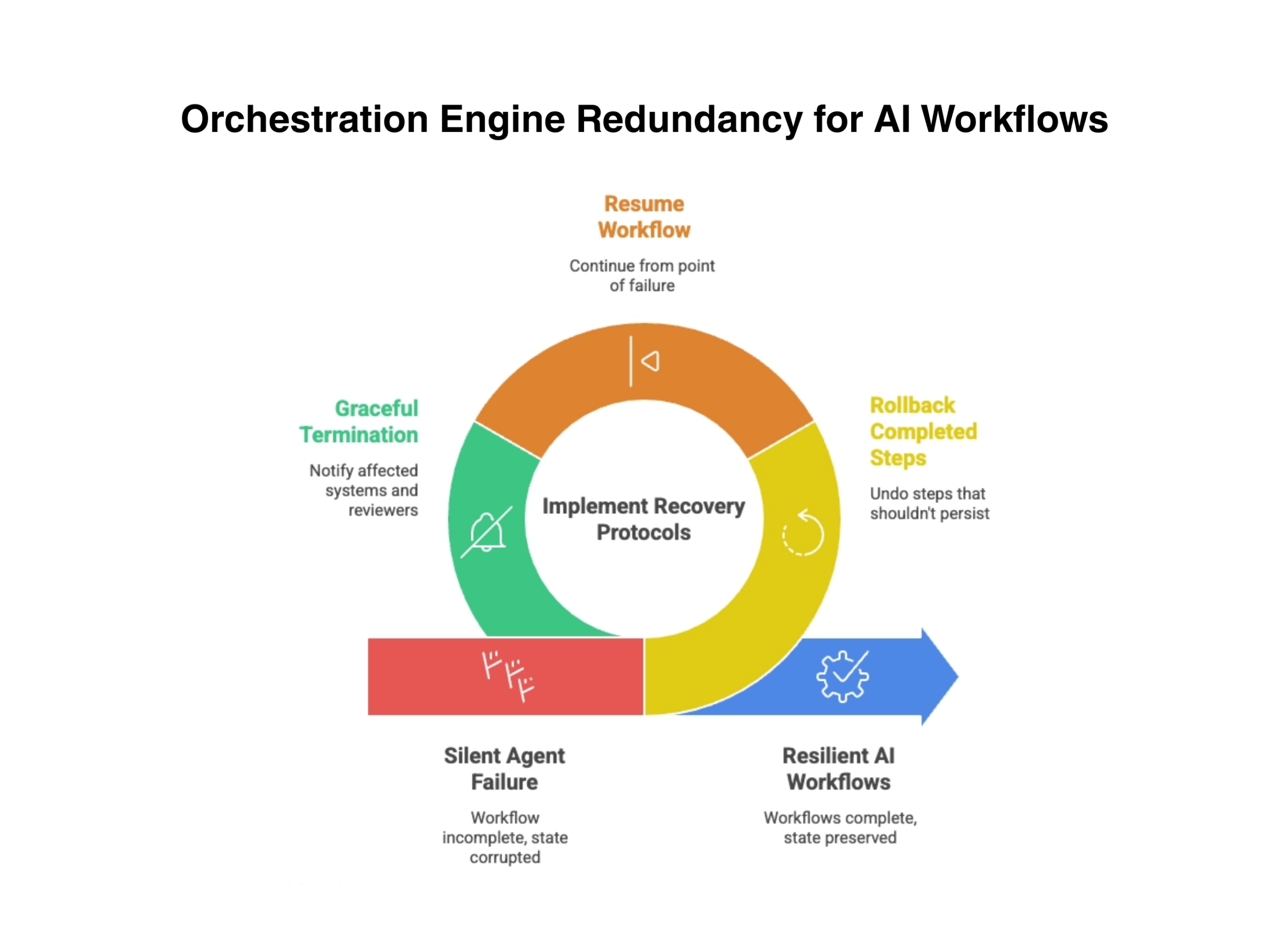
Traditional BCP treats the core system as the critical path. In an AI-driven bank, the orchestration engine — the system that coordinates AI agents, manages workflows, and routes decisions — is equally critical. If the orchestration engine fails, every AI workflow fails with it. Banks need redundancy for this layer that is separate from core system redundancy.
Here is what a partial agent failure actually looks like. It is 3am. An AI agent processing overnight loan applications fails at step seven of a twelve-step workflow. The first six steps have already executed: credit data pulled, identity verified, collateral valuation requested, preliminary decision rendered, compliance flags checked, and a conditional approval letter generated. Steps seven through twelve — final underwriting review, rate lock, document generation, regulatory filing, customer notification, and portfolio booking — never ran. The customer now exists in a state the system was never designed to handle: conditionally approved with a letter generated but no final underwriting, no rate lock, and no regulatory filing. The operations team arriving at 7am finds the agent’s workflow log showing completion through step six and failure at step seven — but no alert was generated because the orchestration engine itself restarted cleanly. The failure is silent. The half-processed application is a compliance exposure, a customer service problem, and an audit finding waiting to happen.
Banks need recovery protocols that can handle these partial failures without corrupting state: rolling back completed steps that should not have persisted, resuming the workflow from the point of failure, or gracefully terminating with appropriate notifications to all affected systems and human reviewers.
Resilient AI workflows depend on orchestration engine redundancy, enabling recovery from silent failures through rollback, resume and controlled termination.
Updating the Resilience Framework
Banks that take AI seriously must update their resilience frameworks — and updating means more than adding a line item to the existing BCP document. It means fundamentally rethinking what resilience means when the system that fails does not have the courtesy to go down.
Model degradation scenarios belong in BCP testing. Not as a theoretical exercise, but as a tabletop scenario with the same rigor banks apply to data center failover drills. What happens when the fraud model drifts? Who detects it? How long does detection take? What is the exposure during the detection gap? Most banks we have worked with cannot answer these questions because they have never asked them.
Orchestration engine failure belongs in disaster recovery plans — with its own recovery time objective separate from core system RTOs. The core might recover in four hours. If the orchestration engine takes twelve, every AI workflow is grounded for eight hours after the core comes back. Banks that have not defined AI-specific RTOs will discover the gap during an actual incident, which is the worst possible time to discover it.
Operations teams need training to recognize invisible AI failure. This is not a technology problem — it is a people problem. The symptoms are not system alerts. They are outcome anomalies: approval rates shifting without policy changes, processing times changing without volume changes, customer complaints clustering in patterns that do not match known system issues. Training operations staff to watch for these patterns is as important as training them to respond to system outages.
The hardest conversation is the one with the board. CIOs presenting AI-specific resilience requirements to a risk committee that has never seen a model drift scenario face a fundamental communication challenge. The committee understands server outages. It understands network failures. It does not yet understand that a model can be running, returning valid responses, and systematically making wrong decisions. That conversation needs to happen before the first AI model goes into production — not after the first invisible failure produces a material loss.
What Comes Next
With governance, regulation, and resilience addressed, the series turns to the vendor dimension. The core banking vendor’s architecture sets the ceiling for a bank’s AI capability — regardless of how strong the bank’s internal strategy is. The next article examines how AI has fundamentally reshaped what banks should evaluate when selecting or renewing a core banking platform.
Where to Start
If your bank is deploying AI models into production workflows and your BCP still treats resilience as a binary question — up or down — the gap is already open. The question is whether you find it through a structured assessment or through an incident.
The CSP Transformation Readiness Scorecard evaluates your resilience framework against AI-specific failure modes — including model drift detection, orchestration redundancy, agent recovery protocols, and the board-level governance conversations most banks have not yet had. It gives leadership teams a structured view of their architectural gaps in under an hour, with clear prioritization of where to act first.
The failure mode described in this article — models that continue operating after they stop being accurate — is the hardest to detect and the most costly to discover after the fact.
If your institution is ready to move from awareness to action, visit coresystempartners.com/contact to start the conversation.
Next article in the series: How AI Reshapes Vendor Selection for Core Banking
Return to: Why AI makes modern core banking architecture non-negotiable
#CoreBankingTransformation #CoreBankingArchitecture



